 IB Docs (2) Team
IB Docs (2) Team

IA marking: Sample 2
 The sample below is based on Baddeley, Thomson & Buchanan's (1975) study of word length effect.
The sample below is based on Baddeley, Thomson & Buchanan's (1975) study of word length effect.
The sample is based on a student's work, but is heavily edited and changes have been made to illustrate different facets of the IA.
The appendices do not include the letter of consent, materials, or the debriefing notes. The appendices do include the raw data and statistical calculations. Failure to include raw data or statistical calculations is penalized in the analysis.
Introduction
There are many theories for how memory functions and what factors affect it. The Working Memory Model was first developed by Baddeley & Hitch (1974) and revised multiple times (Henry, 3). The Working Memory Model suggests that short-term memory is a dynamic and modular process. There are multiple different stores that have different functions and all stores have limited capacity. For recalling speech and auditory-based information, the phonological loop is used, which has two components. The phonological store that can hold information that rapidly decays, and the articulatory rehearsal mechanism which reinputs the memory into the phonological store to refresh the decay. The articulatory rehearsal mechanism also transfers visual information into speech form.
Short Term Memory (STM) is limited in both capacity and duration, as suggested in Miller’s (1956) research. Because phonological STM is described as “rapidly decaying”, if rehearsal takes longer there should be more loss of memory trace, meaning that longer words are more difficult to memorise. This is the “word length effect”, the phenomenon under investigation that supports the Working Memory Model.
The aim of this study is to determine whether word length, defined by the number of syllables, affects an individual's accuracy in recall. If the results of our experiment show that shorter words result in better memory performance, this could have implications for education. Typically longer more complex words are associated with a more sophisticated understanding and have a positive connotation in higher levels of academia; however, this research suggests that education should potentially utilise shorter words for example in lectures.
In this study, the number of syllables in words - either monosyllabic or five-syllables - is the independent variable, and the number of words recalled in the correct order is the dependent variable. The target population is a group of international high school students.
The null hypothesis is that there will be no significant difference in the number of words recalled from a sequence of 8 words whether the words are monosyllabic or five-syllable words.
The research hypothesis is that participants will recall significantly more words from a sequence of 8 words when the sequence is comprised of monosyllabic words than when comprised of five-syllable words.
Exploration
This experiment used a repeated measures design. The different conditions have different lists and thus practice effect, one of the major weaknesses of repeated samples, is less relevant. Using a repeated measures design instead of independent samples allows us to eliminate participant variability - that is, this eliminates the variable that one group had better memory skills than the other. We also counterbalanced, reversing the order that conditions were given to each group to control for order effects.
The sample was an opportunity sample made of high school students from an international school. 14 out of 31 were male, and 6 out of 31 indicated that their mother tongue was English. However, the average proficiency of English should be quite high due to the background of being in an international school. The age range was 14 - 15-years-old. They should have a sizable exposure to more academic five-syllable words and should be fairly familiar with the process of memorising different sequences of words due to an academic context. The sample was obtained by using our school's "advisory block." Participants were randomly allocated to either the "monosyllabic" or the "five-syllable" condition to begin the experiment.
In order to create the list of words, we used the list of words used in the original experimental study. Since they were originally meant to have approximately the same level of occurrence in everyday use, we cross-checked our list of words with online sources such as wordandphrase.info and Google Ngram. We used a pilot study to test levels of familiarity with a small sample of high school students to confirm all words were within common vocabulary.
As a control, we counterbalanced, one group beginning with the list of monosyllabic words and the other group five-syllable words to avoid order effect. Parental and student consent was given (see appendix i) and participants debriefed (see appendix ii). We met all ethical standards and controlled undue stress by explaining that results were anonymised in standardised instructions read to all (see Appendix iii). The participants were allowed to familiarize themselves with the list of words (see Appendix iv) so it was primarily memory span and STM that was being measured, not affected by unfamiliar or unknown words. The participants were played a recording of a sequence of 8 words in random order at a 1.5-sec rate and asked to do a complete recall of the list in order after the recording had ended (see appendix iv). This was done by controlling the length of the sequence read and keeping time in between the start of words constant with a timer in view, resulting in 12-second recordings for 8 words for both trials. This was repeated with the sequence of the other 8 words of differing number of syllables. For each trial, the participants were given 120 seconds, and answer sheets were collected afterward.
Analysis
In order for our data to better reflect our hypothesis, we measured words that were spelled incorrectly but sounded the same as the word on the list. Although we tried to control for this by allowing the participants to familiarize themselves with the words beforehand, differences in spelling would probably have occurred during the encoding stage rather than the retrieval stage (For raw data see appendix v). The results were as follows.
Table 1. Descriptive analysis of data
| Monosyllabic words | 5-syllable words | |
| Mean number of words recalled in the correct order | 2.87 | 1.32 |
| Median | 2 | 1 |
| Standard deviation | 1.65 | 1.01 |
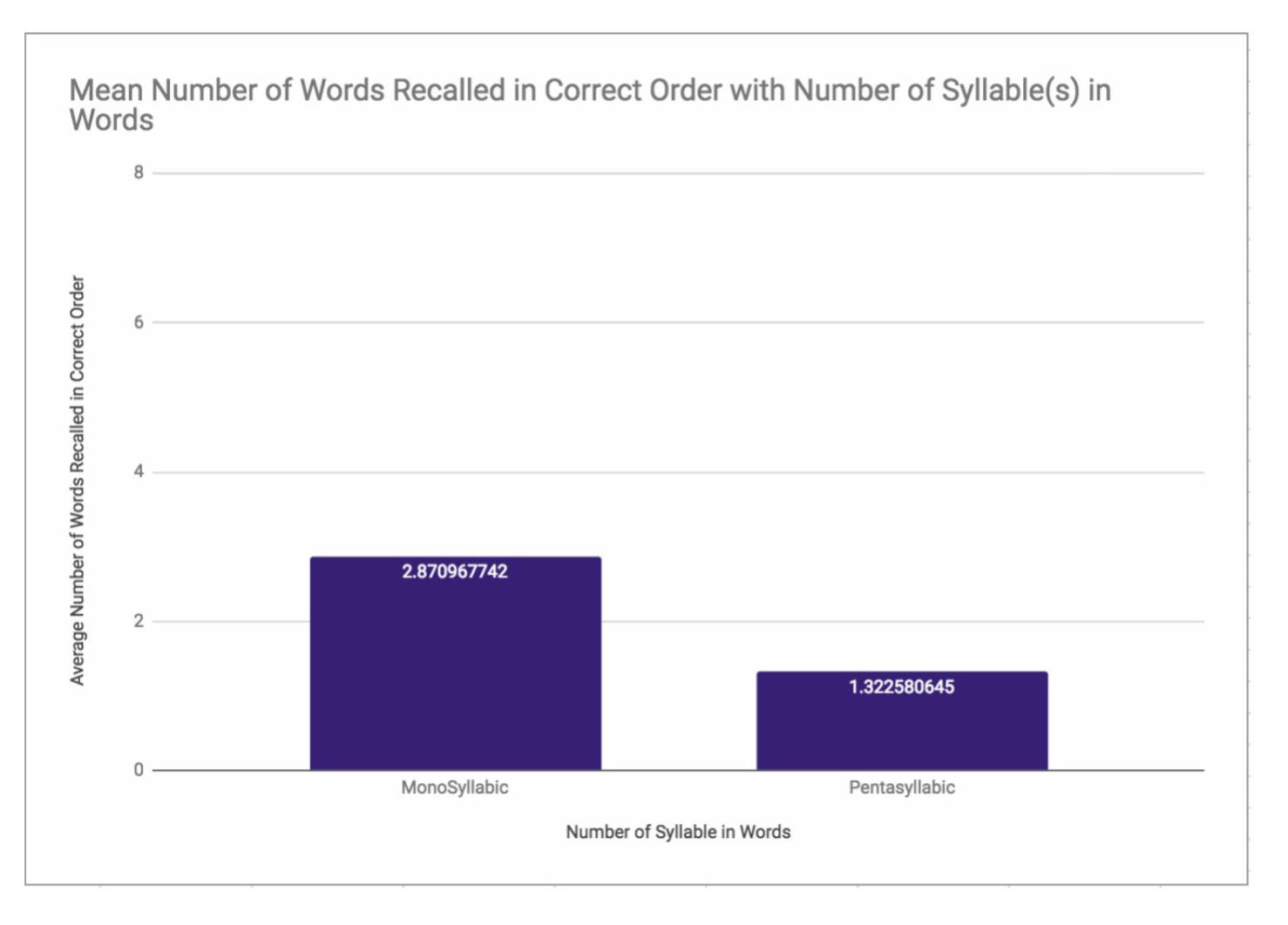
As can be seen from the data above, sequences that constituted of only monosyllabic words were remembered on average ~2.2 times more in the same order as told. This is also reflected by the median, which is twice as large for the monosyllabic condition as the five-syllable condition. The monosyllabic condition also had a higher standard deviation, 1.65 compared to 1.01 of five-syllable words. This corroborates with the theory, as participant variability and differences in STM capabilities would be seen to a larger degree in data as monosyllabic words are split into smaller chunks. However, this participant variability does not affect our causational relationship as we used repeated measures.
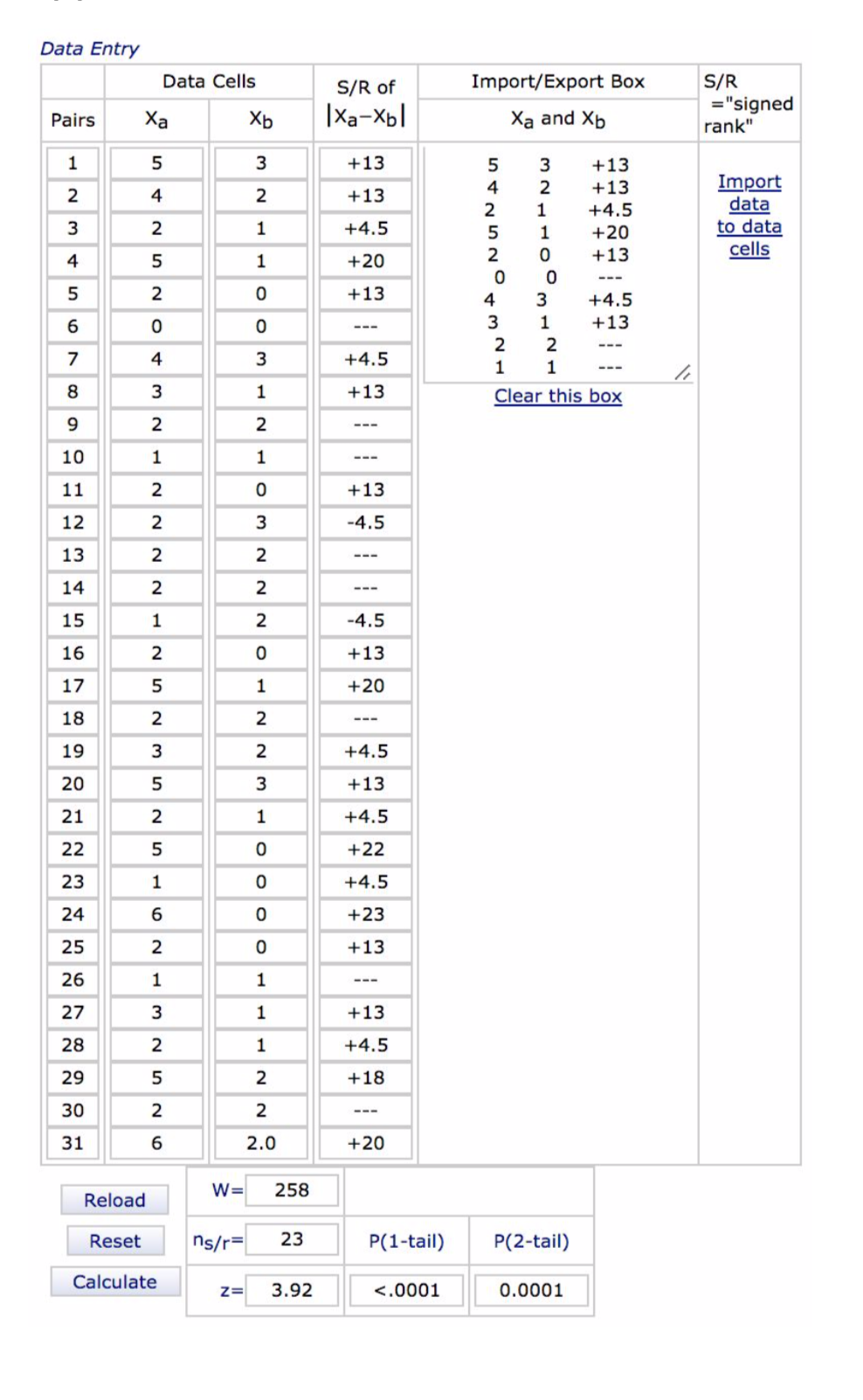
Our data was ratio and we had a sample size over 30; therefore, we can assume that our data was normally distributed and use a dependent T-test (see appendix vi). The results show that the data was significant at p < 0.001. Based on our data, it appears we can reject the null hypothesis. This suggests that there is a significant difference between the number of words remembered in the correct order depending on the number of syllables in those words in international high school students.
Evaluation
As can be seen by the results, we were able to support the findings of Baddeley, Thomson & Buchanan (1975). However, we cannot directly compare our results to those of the original study due to the difference in procedure. Because the original study manipulated two independent variables (the number of syllables and the number of words in a sequence) and repeated each treatment with several trials, their dependent variable was a percentage of sequences recalled entirely correctly. However, we can extrapolate from their data, and tell that the percentage correctly recalled for polysyllabic 8-word sequences was near 0, as no participant recalled all 8 words successfully. However, their monosyllabic 8-word sequences were near 20% fully recalled, while we only had one participant that successfully recalled 6/8 words in the correct order. It could be due to our sample of high school students' short-term memory being less effective compared to university/post-graduate students used in the original study.
The results are supported by the working memory model. Longer words take longer for the articulatory rehearsal to repeat, and thus multiple five-syllable words are more difficult to remember. Our results corroborate with the original studies results.
One of the strengths of our study was that we controlled our list of words for familiarity to high school students. We used both a pilot study to rate the familiarity of all the words by using participants from the same population as our sample. In addition, we checked whether the level of occurrence changed compared to the time period of the original study, using tools such as google Ngram and “word and phrase.info”.
Another strength was how standardized our procedure was, making it replicable and controlling for differences in our trial. Aside from the original standardized instructions read, the entire sequence a recording to control for differences in voice, speed, and intonation. The recording itself was controlled with a 2.5-second interval between each word. The presentation slide to familiarize our participants was also standardized.
The repeated measure design was used to eliminate participant variability, a confounding variable when comparing how the number of syllables affects memory. Although repeated measures are prone to order effects, we controlled those by counterbalancing. However, the fatigue effect may have played a role in the group that started with the polysyllabic list. It is also difficult to know if polysyllabic words have lower rates of successful recall because participants feel the task is more difficult and thus try less, rather than such words being more difficult to memorise.
One limitation was that we didn’t control for fluency in English. Although we recorded each participant's mother tongue to see if there was any correlation, there was no obvious correlation. However, differences in language fluency may impact the process of encoding of more complex polysyllabic words and thus accentuate the difference between our different treatments. This may mean that the difference is not as significant as our data suggests.
In addition, there were many limitations as a result of uncontrolled variables. The participants did not all consistently listen and from observation likely did not try their hardest, although we didn’t observe a direct “Screw you” effect. This may be a result of the participants knowing that data would be anonymised. There was also talking within the treatments which could interfere with memory and partially explain the lower rates of successful recall compared to the original study.
One factor that may impact our findings is how we addressed spelling. Not all words were spelled correctly. We counted those that sounded significantly close enough to the correct word as correct, which means there was potential researcher bias. By the theory of articulatory rehearsal and phonological loop, spelling itself should not be a factor or consequence of a change in word length, and thus is not relevant. The phonological loop stores word information by sound rather than letters, so the accuracy of the letters should not be a factor as long as the sound is similar. We decided this counting of misspelt words was more reflective of what the study actually attempts to measure.
For future research, one modification to address some issues would be to have the participants rehearse it orally, which both eliminates problems of spelling but also because of personal interaction would likely help incentivise the participants to do better.
From our study, we are able to conclude that the number of syllables in words directly affects the number of words successfully recalled, with monosyllabic words recalled at a significantly higher rate.
Works cited
Baddeley, Alan D., et al. “Word Length and the Structure of Short-Term Memory.” Journal of Verbal Learning and Verbal Behavior, vol. 14, no. 6, Dec. 1975, pp. 575–589., doi:10.1016/s0022-5371(75)80045-4.
Henry, Lucy. “The Working Memory Model.” The Development of Working Memory in Children, 2011, pp. 1–36., doi:10.4135/9781446251348.n1.
Appendix i. Raw data
Number of words recalled in the correct order
| Participant | Short words | Long words |
| 1 | 5 | 3 |
| 2 | 4 | 2 |
| 3 | 2 | 1 |
| 4 | 5 | 1 |
| 5 | 2 | 0 |
| 6 | 0 | 0 |
| 7 | 4 | 3 |
| 8 | 3 | 1 |
| 9 | 2 | 2 |
| 10 | 1 | 1 |
| 11 | 2 | 0 |
| 12 | 2 | 3 |
| 13 | 2 | 2 |
| 14 | 2 | 2 |
| 15 | 1 | 2 |
| 16 | 2 | 0 |
| 17 | 5 | 1 |
| 18 | 2 | 2 |
| 19 | 3 | 2 |
| 20 | 5 | 3 |
| 21 | 2 | 1 |
| 22 | 5 | 0 |
| 23 | 1 | 0 |
| 24 | 6 | 0 |
| 25 | 2 | 0 |
| 26 | 1 | 1 |
| 27 | 3 | 1 |
| 28 | 2 | 1 |
| 29 | 5 | 2 |
| 30 | 2 | 2 |
| 31 | 6 | 2 |
Appendix ii. T-test calculations
Assessment
Introduction (max 6 marks)
The aim of the investigation is stated and its relevance is explained, although the relevance could be more developed and/or specific (5 marks); the theory or model upon which the student’s investigation is based is described and the link to the student’s investigation is explained. Once again, this link could be more developed (5 marks); The independent and dependent variables are stated and operationalized in the null or research hypotheses (6 marks).
Total: 5 marks
Exploration (max 4 marks)
The research design is explained - that is, it is clear why a repeated measures design was chosen and not independent samples. (4 marks). The sampling technique is correctly identified and there is some explanation, but this could be more clearly explained. (3 marks); the choice of participants is explained, but not well developed (3 marks); two controls are explained - the use of counterbalancing and the recording of the lists (4 marks); the choice of materials is explained - that is, the use of the original list and then confirming that these words are familiar to international high school students (4 marks).
Total: 4 marks
Analysis (max 6 marks)
Descriptive and inferential statistics are appropriately and accurately applied. (6 marks) The graph is correctly presented and addresses the hypothesis (6 marks). The statistical findings are interpreted with regard to the data and linked to the hypothesis. Discussion of the median could be a bit more developed. (5 marks).
Total: 6 marks
Evaluation (max 6 marks)
One modification is identified and described but not explained. A limited discussion of modifications (3 marks); The findings of the student’s investigation are discussed with reference to the background theory or model, but this could be more focused (4 marks). Strengths and limitations of the design, sample and procedure are stated and explained and relevant to the investigation. (6 marks)
Total: 5 marks
Total marks
Total: 20 marks
IB 7 Twitter
Twitter
 Facebook
Facebook
 LinkedIn
LinkedIn