 IB Docs (2) Team
IB Docs (2) Team

IA Exemplar High
 The sample below is one of three exemplars of the same experiment, there is a "high", a "mid" and a "low" scoring internal assessment.
The sample below is one of three exemplars of the same experiment, there is a "high", a "mid" and a "low" scoring internal assessment.
The experiment by Rogers, Kuiper, and Kirker (1977), which focuses on the self-reference effect, can be found here.
The appendices do not include the letter of consent, materials, or the debriefing notes. The appendices do include the raw data and statistical calculations. Failure to include raw data or statistical calculations is penalized in the analysis.
Introduction
There are many theories as to what factors may affect our ability to recall information. The Levels of Processing theory was developed by Craik & Tulving (1975). The researchers proposed that the depth to which we process information determines the likelihood that we will recall it. In their classic study, the researchers presented participants with a series of words; each word was followed by a simple yes or no question. Some of the questions led to shallow processing - for example, did the word start with the letter “s”? At the deep level of processing, participants were asked if words fit within the context of a sentence. Following the task, participants were asked to read a list of words and determine which words were part of the original list and which words were new. Results of the study indicated that participants' memories were more accurate for words that they had processed at a deeper level.
Rogers, Kuiper, and Kirker (1977) took Craik & Tulving’s study a step further by proposing “the self-reference effect” - that is, “the tendency for individuals to have better memory for information that relates to oneself in comparison to material that has less personal relevance” (Mandernach). In their study they replicated the study done by Craik & Tulving (1975), using a sample of 32 first-year psychology students. Participants were shown a list of forty words and then asked either a shallow processing question or a question that would lead to self-referent encoding, such as “Does this describe you?” After answering the questions about the words, the participants were given a piece of paper and asked to recall the words in any order. The findings showed that participants in the self-reference condition remembered 8.35 times as many words as those in the structural condition. The theory argues that the participants process the information more deeply when they make a personal connection.
The aim of this study is to determine whether the self-reference effect increases the recall of a list of words among international, multi-lingual teenagers. It is an interesting question to investigate as it potentially supports the idea that if what we learn in school is relevant to our own identity, then we should be able to recall it better than if there is no personal relevance attached to it. This evidence could be used to support changes in both what is taught in schools - and how it is taught.
The null hypothesis is that there will be no difference in the mean number of words recalled from a list of 40 words whether the participant engages in shallow processing or self-referent encoding.
The research hypothesis is that participants who use self-referent encoding will recall more words on average from a list of 40 words than participants who engage in shallow processing.
The independent variable is the level of encoding (structural or self-referent); the dependent variable is the number of words recalled from the original list. Self-referent encoding will be accomplished by asking participants if a word describes them. Shallow processing will be accomplished by asking participants the structural question if the word has the letter “e.”
Exploration
This experiment used an independent samples design. Each group was either given questions that would lead to shallow processing or to self-referent encoding. It would not have been possible to test each participant in both conditions and use the same list of words, so an independent samples design was used. We also chose not to mix the two sets of conditions in one group because we were concerned that the participants would guess the aim of the study, leading to expectancy effects.
The sample was made up of two IB English classes. There were 32 participants - with 15 (6 males, 9 females) in the shallow processing condition and 17 (5 males, 12 females) in the self-referent condition. A sample of opportunity was used, guaranteeing that the sample was easily organized. In this case, it also meant that the participants had a relatively similar level of English proficiency, which is important when asking participants to recall vocabulary. Also, by using IB students we were hoping that we would have a more motivated sample, seeing as how they understood the importance of the internal assessment. The sample consisted of 24 students whose mother-tongue was not English.
With regard to ethical considerations, we had our participants sign a letter of consent (see appendix i). At the end of the experiment, the participants were debriefed (see appendix iii)
There were several controls in the experiment. In each condition, participants were read the standardized directions (see Appendix ii). Participants watched the 40 words projected in a Powerpoint slideshow. The slides were timed for 15 seconds so that the amount of time that they saw the word was standardized. After the list was complete, participants were shown the video “Funny Animal Videos” as a distractor task. This was to make sure that words were not still in STM to avoid the recency effect. They were given 2 minutes to complete the task. New paper was distributed to make sure that no one had written down some of the words, anticipating that they would be asked to recall them.
In order to create a list of words, we first consulted websites for lists of positive and negative personality adjectives (EnglishClub). We chose 20 positive and 20 negative words. In addition, as a control, we chose only words with more than one syllable in order to avoid the word length effect having an influence on our data. Additionally, we made sure that only half of them had the letter “e.” We then took the list of words to our IB Psychology class and asked them if they knew all of the words. Words that were unfamiliar to any member of our class were replaced with words that were more familiar.
Analysis
The following chart shows the descriptive statistics from our data.
Table 1. Descriptive analysis of data
| Shallow processing | Self-referent processing | |
| Mean recall | 9.33 | 20.35 |
| Standard deviation | 2.89 | 4.70 |
Graph 1. Boxplot showing distribution of data
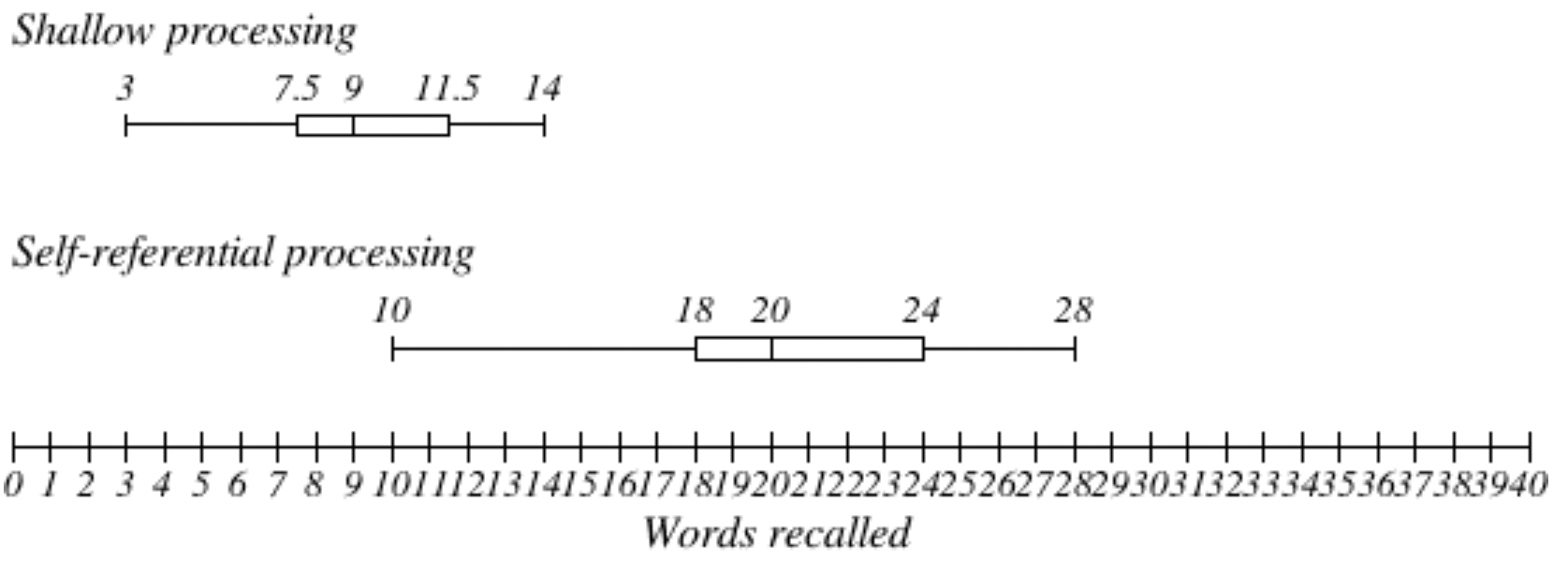
The boxplots above show that the data is not overlapping in the two conditions. The median for the shallow processing group is 9.0 and 20.0 for the self-referential group. The IQR is very similar for the two conditions, with 4.0 for the shallow and 6.0 for the self-referential condition. In addition, we can see in both conditions that the data tends to skew toward the right, showing a higher variation of recall above the median than below the median.
Graph 2. Bar graph showing the differences in mean recall for different levels of processing.
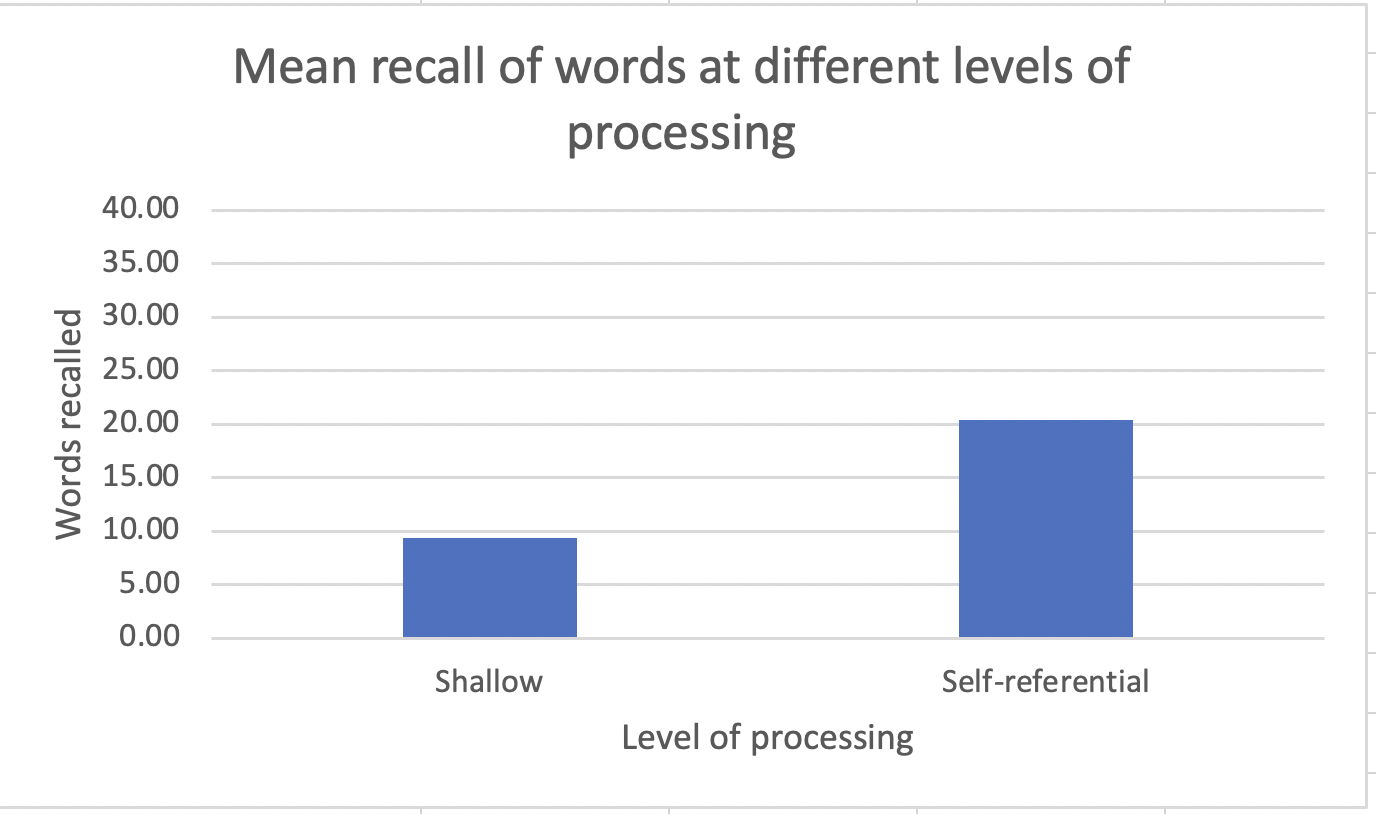
As can be seen from the data above, it appears that on average recall for the group that used self-referential encoding was 2.18 times as many words as the group that used shallow processing. As the mean and the median of the data set are relatively similar, this indicates that the data set is relatively symmetrical, although the box plots show a slight skew to the right. In the self-referent group, there was a greater variance in the data. This can also be seen in the range of the data. In the shallow processing group, the range was from 3 - 14; whereas in the self-referent group there was a range from 10- 28. The variation in the scores in both groups could be due to language proficiency or level of motivation. In the shallow processing group, it is also possible that the participants engaged in deeper processing that could not be observed by the researchers.
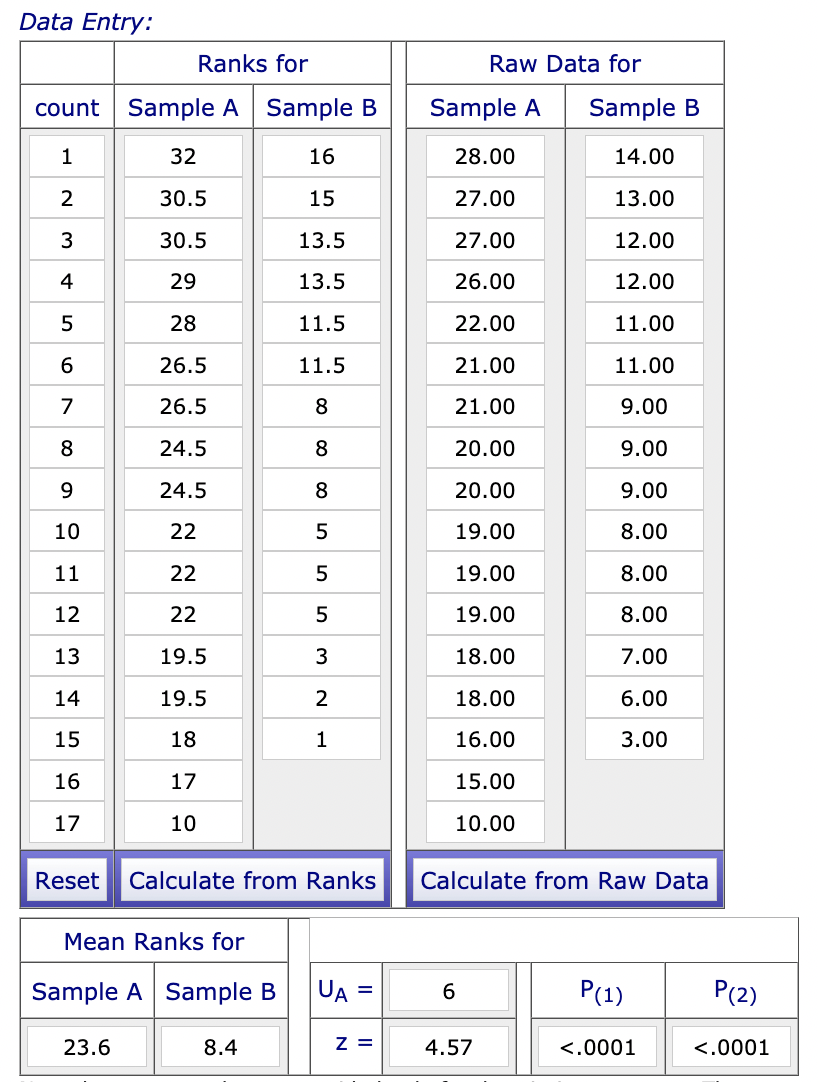
Since we had a small sample size, used an independent samples design, and our data was ratio, we used a Mann-Whitney U test. A Mann-Whitney U test indicated that there was a significant difference between the average number of words recalled when "shallow processing" was used (Mdn = 9 ) and for when self-referent processing was used (Mdn = 20), U = 6.0, p < 0.001. This means that we can reject the null hypothesis. It appears that self-referential encoding leads to great recall than shallow processing when asked to recall a list of adjectives.
Evaluation
As can be seen by the results stated above, we were able to support the findings of Rogers, Kuiper & Kirker (1977). The mean number of words recalled in the self-referential encoding group was greater than in the shallow processing group. The results are supported by the theory of levels of processing. Self-referential encoding is reflective and gets the participants to make personal links between themselves and the word. This gives the memory meaning and leads to a deeper level of processing that will make the retrieval of the information easier.
A strength of the independent samples design was that we could use the same list of words in both conditions. This meant that no confounding variables would be introduced by having a second list of words - for example, that the words were less familiar or more difficult to recall. A limitation of the design was that it did not control for participant variability. This could be addressed by using a repeated measures design, with different words processed at either the shallow or self-referent level. This would eliminate any difference between the participants’ skill of recall since all participants would be compared to themselves in each condition. However, the conditions would have to be counter-balanced in order to avoid order effects.
One strength of our sample was that it was easily obtained and they were all in the same grade level - meaning that they shared a common level of education. However, there were also variables that could not be well controlled because of the nature of our sample. The level of English proficiency was not controlled, so this could have had an effect on the level of recall. Secondly, it is not possible to know whether the group that was asked to do shallow processing actually did so, or if they used deeper processing - for example, visual imagery. It is not possible to control for this, but we did ask the participants during the debriefing. None of them said that they did, but this is self-reported information. Although it may be what the participants believe to be true, it may not represent what actually happened.
One of the strengths of our procedure was that we tried to adapt our list of adjectives for our own community. This did not, however, prevent us from having some words that participants did not recognize. During the debriefing, we asked our participants whether there were any words that they did not know. We found that two participants did not know the meaning of flirtatious and three did not know gullible. If we were to replicate this, we would replace these words with something more common. In hindsight, it may have been better to test the words on a younger group, with the hope of avoiding having a lack of understanding as a confounding variable. Another strength of the procedure was that we had the Powerpoint set up to show the words for the same amount of time. This controlled for human error and guaranteed that there was no variation between the two groups.
Another limitation of the procedure is that there may have been an expectancy effect - that is, the participants may have guessed that we were going to ask them to recall the words that they were being shown. In our school, students are participants in many experiments and many experiments ask students to recall the words. This may mean that in anticipation of having to recall the words, the participants rehearsed the words.
From our study, we are able to conclude that self-referential encoding leads to greater recall of words than shallow processing.
Works cited
Craik, F. I. M., & Tulving, E. (1975). Depth of processing and the retention of words in episodic memory. Journal of Experimental Psychology: General, 104, 268-294.
Dailymotion. Funny Animal Videos. http://www.dailymotion.com/video/x19a02g_funny-animal-videos_animals
EnglishClub. (n.d.) Negative Personality Adjectives List. https://www.englishclub.com/vocabulary/adjectives-personality-negative.htm
EnglishClub. (n.d.) Positive Personality Adjectives List. https://www.englishclub.com/vocabulary/adjectives-personality-positive.htm
Mandernach, Jean. (n.d.) Self Reference. Online Psychology Laboratory. Accessed January 1, 2015. http://opl.apa.org/Experiments/About/AboutSelfReference.aspx
Rogers, T. B., Kuiper, N. A., & Kirker, W. S. (1977). Self-reference and the encoding of personal information. Journal of Personality and Social Psychology, 35, 677-688.
Appendix i. Raw data
| Shallow | 8 | 12 | 14 | 11 | 9 | 7 | 12 | 8 | 3 | 13 | 9 | 6 | 8 | 9 | 11 | ||
| Self-referential | 22 | 28 | 19 | 15 | 21 | 19 | 16 | 10 | 27 | 19 | 27 | 21 | 18 | 20 | 26 | 20 | 18 |
Appendix ii. Inferential calculations
Assessment
Introduction
The aim of the investigation is stated and its relevance is explained." The theory or model upon which the student’s investigation is based is described and the link to the student’s investigation is explained." The independent and dependent variables are stated and operationalized in the null or research hypotheses. 6 marks.
Exploration
The research design is explained. The sampling technique is explained. The choice of participants is explained. Controlled variables are explained. The choice of materials is explained. 4 marks
Analysis
Descriptive and inferential statistics are appropriately and accurately applied. The graph is correctly presented and addresses the hypothesis. The statistical findings are interpreted with regard to the data and linked to the hypothesis. 6 marks
Evaluation
The findings of the student’s investigation are discussed with reference to the background theory or model. Strengths and limitations of the design, sample and procedure are stated and explained and relevant to the investigation. Modifications are explicitly linked to the limitations of the student’s investigation and fully justified. 6 marks
Total marks: 22 marks
 Twitter
Twitter
 Facebook
Facebook
 LinkedIn
LinkedIn